PostgreSQL Scaling Patterns: From Single Node to Distributed
A progressive guide to scaling PostgreSQL through connection pooling, read replicas, partitioning, and sharding — with configuration examples and performance benchmarks.

Akhil Sharma
February 2, 2026
PostgreSQL Scaling Patterns: From Single Node to Distributed
PostgreSQL scales further than most teams expect. Before reaching for a distributed database, you can handle millions of rows per second on a single instance with the right configuration. Here's the progression, from quick wins to architectural changes.
Level 0: Tune What You Have
Most PostgreSQL performance problems are configuration problems. The default settings are conservative — designed for a system with 128MB of RAM.

Index audit. Before anything else, find your slow queries and missing indexes:
Level 1: Connection Pooling
PostgreSQL forks a new process for each connection. At 500+ connections, the process overhead (memory, context switching, lock contention) degrades performance. Connection pooling is the first scaling move.
PgBouncer is the standard:
Pool modes and their trade-offs:
| Mode | Connection Release | Prepared Statements | SET commands | Use Case |
|---|---|---|---|---|
| Session | On disconnect | Yes | Yes | Legacy apps |
| Transaction | After COMMIT/ROLLBACK | No* | No* | Most apps |
| Statement | After each query | No | No | Simple queries |
PgBouncer 1.21+ supports prepared statements in transaction mode with max_prepared_statements.
Sizing formula: pool_size = (num_cores * 2) + effective_spindle_count. For SSD, use num_cores * 2 + 1. A 16-core server needs ~33 connections. Going above this rarely helps and often hurts due to lock contention.
Level 2: Read Replicas
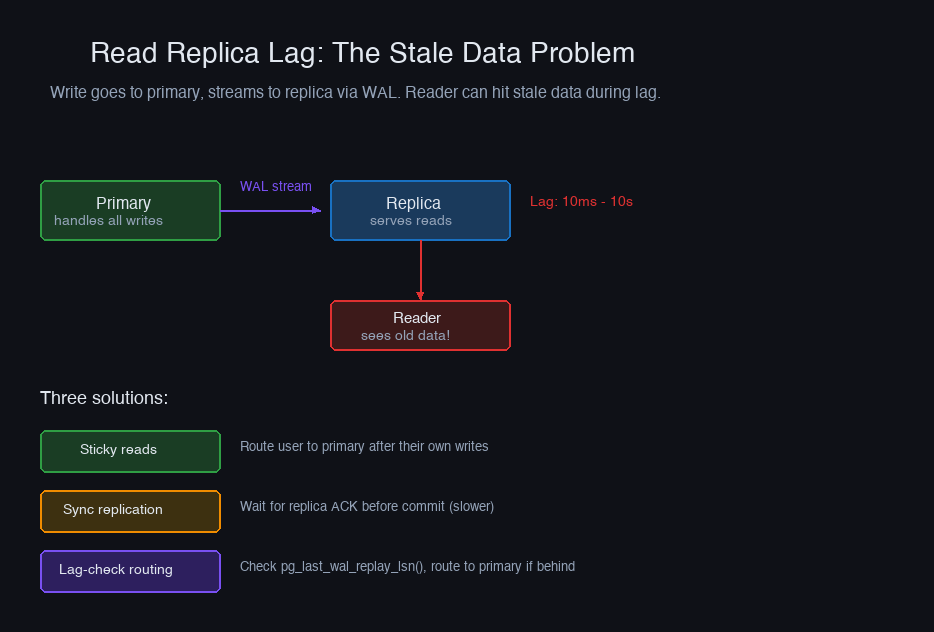
Streaming replication sends WAL records from the primary to replicas. Replicas can serve read queries, distributing read load.
Advanced System Design Cohort
We build this end-to-end in the cohort.
Live sessions, real systems, your questions answered in real time. Next cohort starts 2nd July 2026 — 20 seats.
Replication lag is the key concern. Writes go to the primary, replicas catch up asynchronously. A user writes data and immediately reads from a replica — they don't see their write. Solutions:
- Route writes and their subsequent reads to the primary. After a write, stick the user to the primary for a few seconds.
- Use synchronous replication for critical replicas (at the cost of write latency).
- Check replication lag before routing:
Level 3: Table Partitioning
When single tables exceed 100M+ rows, operations like VACUUM, index rebuilds, and sequential scans become expensive. Partitioning splits a table into smaller physical tables while presenting a single logical table.
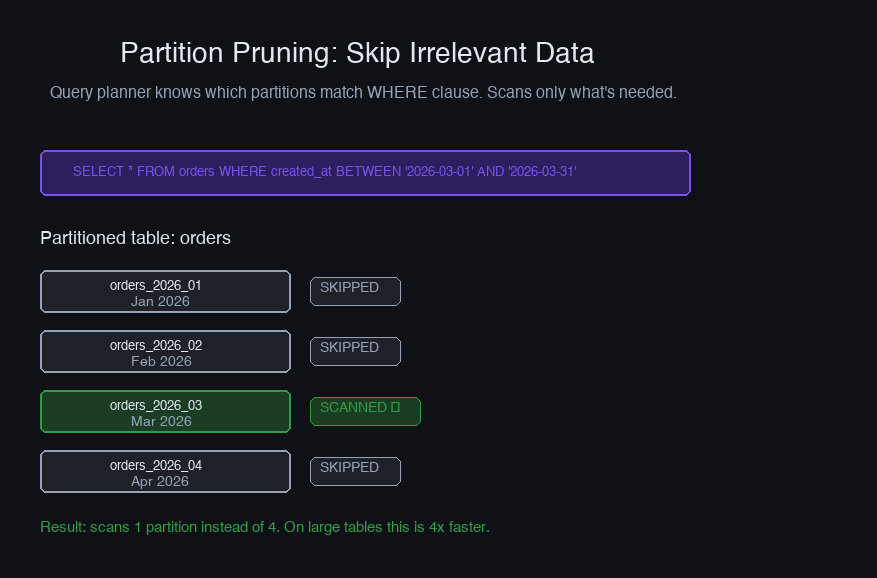
Partition pruning makes queries fast: a query with WHERE created_at >= '2026-02-01' only scans the relevant partitions, skipping months of data.
Automate partition creation. Don't create partitions manually — use pg_partman or a cron job:
Partition types:
- Range: Time-series data, logs, events. Most common.
- Hash: Even distribution when there's no natural range. Good for sharding by user_id.
- List: Categorical data (status, region, tenant).
Level 4: Sharding with Citus
When a single PostgreSQL instance can't handle the write load or the data volume, you need horizontal sharding. Citus extends PostgreSQL with distributed tables.
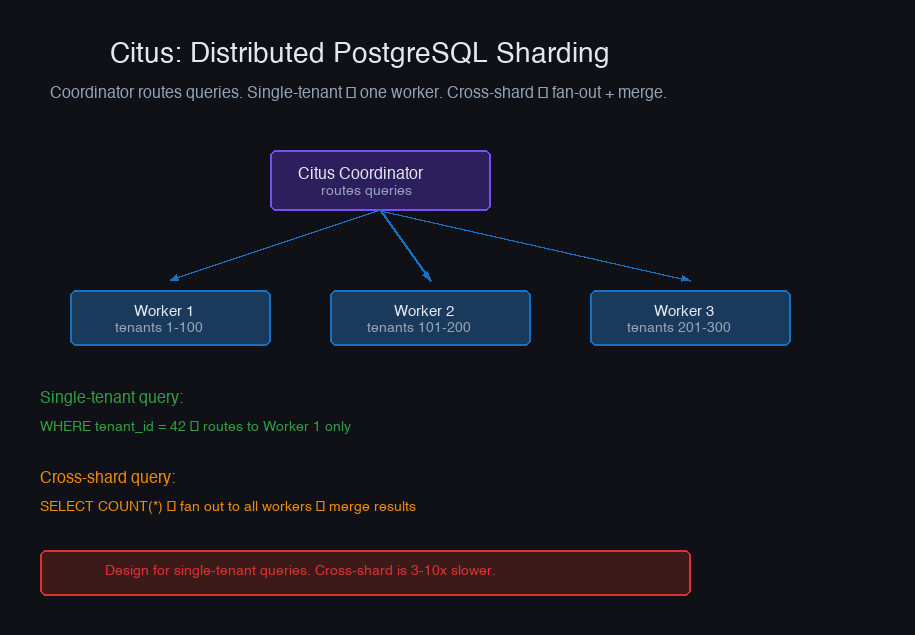
Shard key selection is the most critical decision. A good shard key:
- Has high cardinality (many distinct values)
- Is present in most queries (enables single-shard execution)
- Distributes data evenly
- Is stable (doesn't change after insert)
For SaaS applications, tenant_id is almost always the right shard key. For social networks, user_id. For time-series, composite keys or hash partitioning.
Co-location: Tables that are frequently joined should be sharded on the same key. Citus supports co-locating distributed tables so that rows with the same shard key live on the same worker:
When to Consider Alternatives
PostgreSQL scaling has limits. Consider other options when:
| Signal | PostgreSQL Answer | Alternative |
|---|---|---|
| > 100K writes/sec sustained | Citus, but complex | ScyllaDB, DynamoDB |
| > 50TB data, append-only | Partitioning, archival | ClickHouse, BigQuery |
| Schema-free, highly nested documents | JSONB works to a point | MongoDB, DynamoDB |
| Sub-millisecond key-value lookups | Not PostgreSQL's strength | Redis, DragonflyDB |
| Global distribution with low latency | Not natively supported | CockroachDB, Spanner |
VACUUM: The Scaling Tax
PostgreSQL's MVCC creates dead tuples on every UPDATE and DELETE. VACUUM reclaims this space. At scale, VACUUM becomes a significant operational concern.

Tune autovacuum for high-churn tables:
For tables with billions of rows, consider using partitioning specifically to make VACUUM manageable — dropping old partitions is instant, while vacuuming a billion-row table takes hours.
The scaling path is predictable: tune, pool, replicate, partition, shard. Each step buys you an order of magnitude. Most applications never need to go past read replicas. If you find yourself reaching for sharding, make sure you've exhausted the simpler options first — they're easier to operate, easier to debug, and often sufficient.
More in System Design
Building a Distributed Job Scheduler
Why single-node job schedulers silently fail in production, and how to build a distributed scheduler with leader election, task deduplication, and failure recovery.
Consistent Hashing in Practice
Why modulo hashing silently nukes your cache every time you scale, and how consistent hashing solves the rebalancing problem that takes down databases.