Consistent Hashing in Practice
Why modulo hashing silently nukes your cache every time you scale, and how consistent hashing solves the rebalancing problem that takes down databases.

Akhil Sharma
April 3, 2026
Consistent Hashing in Practice
You have 10 cache servers. Every request hashes its key, mods by 10, and lands on one of them. Simple, fast, evenly distributed. It works perfectly.
Then traffic doubles and you add an 11th server.
In the next 60 seconds, your database receives roughly 10x its normal query load. On-call engineers scramble. The incident post-mortem calls it a "cache miss storm." But it wasn't random bad luck — it was a mathematical certainty you built into your system on day one, and it was always going to fire the moment you scaled.
The problem is % 10 and % 11 are completely different functions. When you move from 10 to 11 servers, hash(key) % 10 produces different results than hash(key) % 11 for almost every key. Not some keys. Not most keys. Around 90% of your cached data just became unreachable — mapped to a different server than where it lives. Every miss cascades to the database. The database, which was comfortably serving cache misses for 10% of traffic, is now handling 90%. It buckles.
This is the modulo hashing failure mode. It's not an edge case — it's the inevitable outcome of any system where number of nodes can change. And in production, the number of nodes always changes eventually.

The Insight That Changes Everything
The core problem with modulo hashing is that adding or removing a single node remaps nearly the entire keyspace. What you need instead is a hashing scheme where adding or removing a node only affects the keys that were "owned" by that node — roughly 1/N of the total keyspace, where N is the number of nodes. Everything else stays put.
Consistent hashing achieves exactly this. The basic idea: imagine a ring that goes from 0 to 2³²-1. You place each server at a position on this ring by hashing the server's identifier (its IP or name). When a key comes in, you hash it too, find its position on the ring, and walk clockwise until you hit a server. That server owns the key.
To make it concrete:
Each server owns the arc between itself and its predecessor. Four servers spaced across the ring divide the keyspace into four roughly equal slices. When a server is added or removed, only the arc it claims is affected.
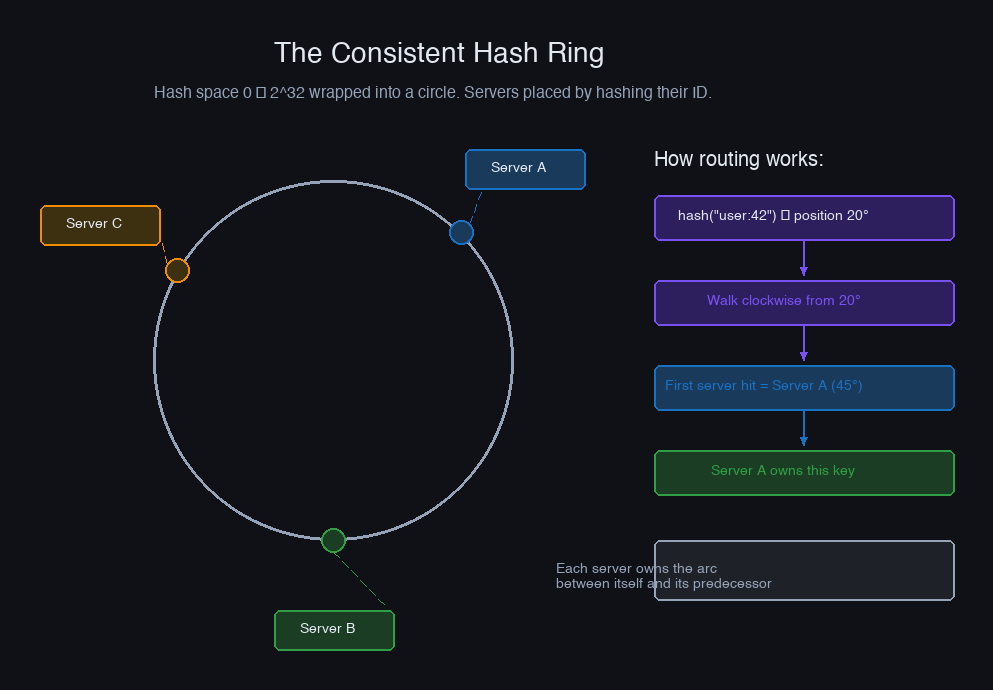
Keys Route to Their Nearest Server
Once servers are on the ring, every key hashes to a position and routes clockwise to the nearest server. The routing is deterministic: given the same ring state, the same key always lands on the same server. No central coordination required.
Now add a new server — Server D — that hashes to 80°:
The only keys that move are the ones in the arc between Server D and its predecessor on the ring. Add a node, move 1/N of the data. Remove a node, redistribute its keys to its successor. The rest of the ring is untouched.
This is the property that makes consistent hashing valuable: bounded disruption. You never nuke your entire cache to add capacity.

The Problem With Naive Consistent Hashing
Here's what the textbooks leave out: placing N servers on a ring with a single hash each gives you terrible load distribution.
Hashing is random. If you have 3 servers, their positions on the ring are essentially random. You might get this:
You've paid for three servers and one is doing half the work. Worse, you won't notice until Server C starts falling over under load — by which point the damage is done.
Advanced System Design Cohort
We build this end-to-end in the cohort.
Live sessions, real systems, your questions answered in real time. Next cohort starts 2nd July 2026 — 20 seats.
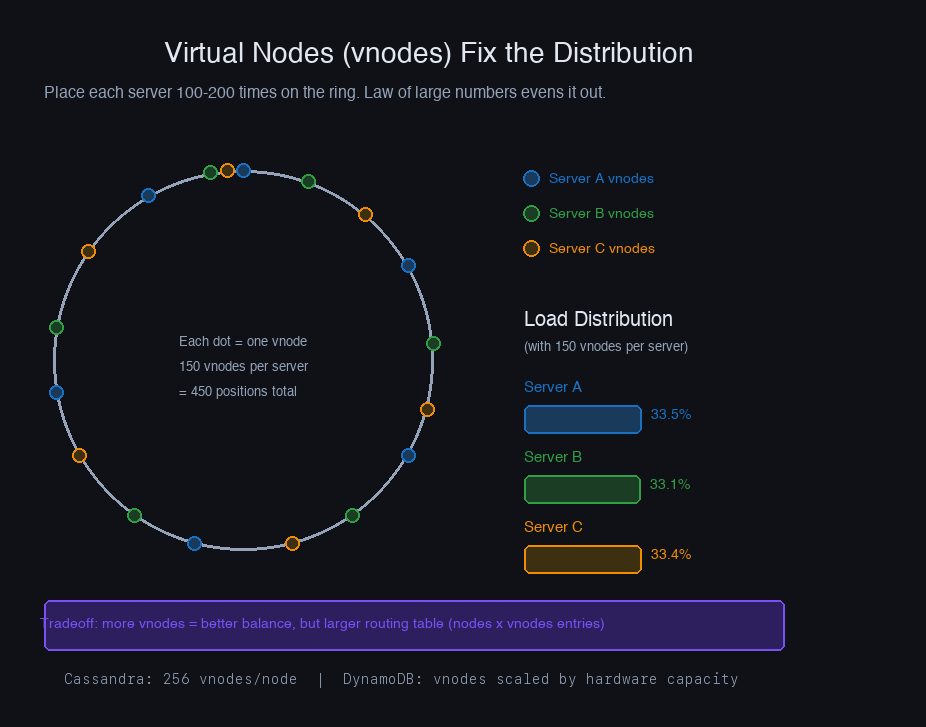
The fix is virtual nodes (vnodes). Instead of placing each server once on the ring, you place it 100–200 times using different hash inputs — "ServerA-1", "ServerA-2", ..., "ServerA-150". Each physical server now has 150 positions distributed across the ring, and by the law of large numbers, the distribution averages out.
With 150 vnodes per server, empirical load distribution typically lands within 5–10% of perfect balance. With 10 vnodes, you can see 50%+ variance. The number of vnodes is a direct dial between memory overhead (more vnodes = larger routing table) and distribution quality.
Production systems like Cassandra default to 256 vnodes per node. Amazon's DynamoDB, as described in the Dynamo paper, uses vnodes to handle heterogeneous hardware — a server with twice the capacity gets twice the vnodes and proportionally more traffic.
What Rebalancing Actually Looks Like
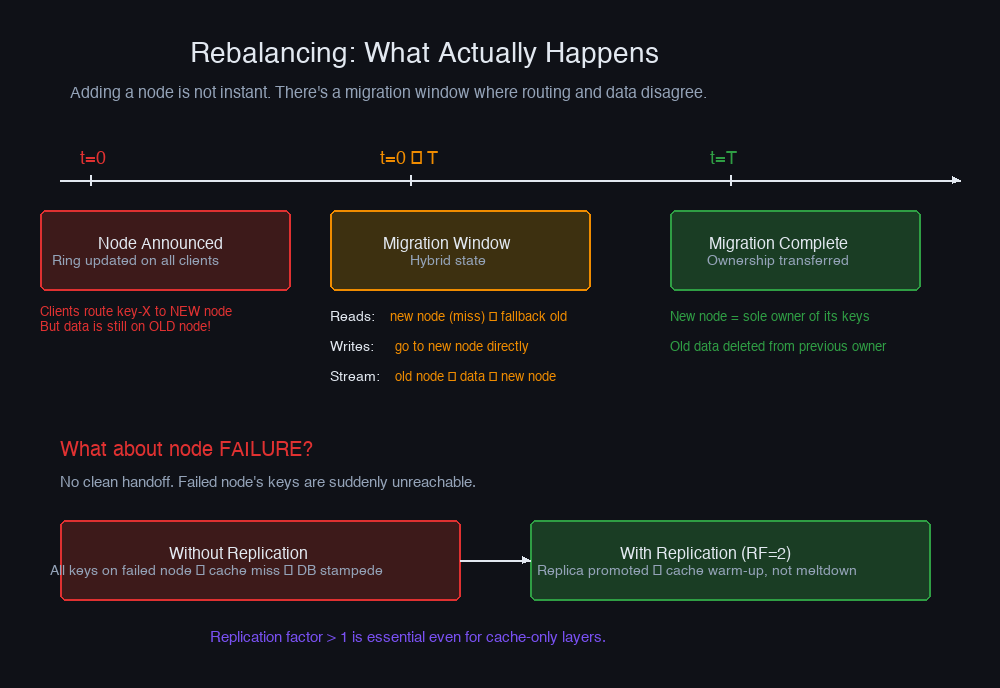
The textbook explanation makes rebalancing sound clean: "Add a node, move 1/N of keys, done." The reality has sharp edges.
When you add a node, requests for the keys that are migrating are in flight. New requests should go to the new node. Old requests are still talking to the old node, and the data isn't there yet. You have a window where your routing table says one thing but the data hasn't moved yet.
Cassandra handles this with a streaming protocol: when a new node joins, it contacts its neighbours and streams the token ranges it's taking over. During the stream, the new node rejects writes for those ranges (the old node still handles them), and after the stream completes, ownership flips. The migration window can be minutes to hours depending on data volume — that entire time, you're running a hybrid state.
Node failure is messier. You don't get a clean handoff. The failed node's keys are suddenly unreachable. If you have replication (and you should), the replicas are promoted immediately. But if you're using consistent hashing for a pure cache layer without replication, a node failure is a cache miss for all keys that node owned — you fall through to the backing store and hope it holds the load.
This is the argument for replication factor > 1 even in caching systems. Cache nodes failing during traffic spikes is extremely common (memory pressure, OOM kills, hardware failure under load). A replication factor of 2 means any single node failure is a cache warm-up problem, not a database meltdown.
Implementing the Ring
A minimal consistent hashing ring in Python:
bisect_right does the "walk clockwise" step in O(log N) time, where N is the total number of vnode positions. With 10 nodes and 150 vnodes each, that's 1,500 positions in the sorted list — bisect_right finds the right one in ~10 comparisons.
The % len(self.ring) handles the wrap-around: if the key hashes to a position past the last node on the ring, it wraps to the first node, completing the circle.
To verify the distribution holds up with 150 vnodes:
Even distribution without tuning. Drop vnodes to 10 and you'll see swings of ±15%.
Where Consistent Hashing Actually Gets Used
Cache clusters are the canonical use case. Memcached, Redis Cluster, and most client-side cache sharding libraries all use consistent hashing. The reason is exactly the scenario in the opening: caches are scaled frequently, and every time you scale, you need the disruption to be bounded. Consistent hashing is why you can add a cache node during a traffic spike without triggering a stampede.
Distributed databases use it to decide which node owns which key range. Cassandra's token ring is consistent hashing. DynamoDB's partition scheme is consistent hashing. The key innovation these systems added was replication — each key is assigned to N consecutive nodes on the ring, so any single node failure still leaves the data accessible.
Load balancers use it for session affinity with fault tolerance. Sticky sessions via IP hash use hash(client_ip) % N — which breaks on any scaling event. Consistent hashing-based sticky sessions keep clients routed to the same backend through node additions and failures, only moving clients whose backend is the affected node.
Where you probably don't need it: if you're sharding a database with a fixed number of shards that you'll never change, modulo is fine. The complexity of consistent hashing pays off when your node count changes frequently, which is more common in ephemeral cache tiers and autoscaling systems than in databases where resharding is a deliberate, infrequent operation.
The Tradeoffs You Take On
Nothing about consistent hashing is free. The virtual node approach introduces a routing table that grows with nodes × vnodes entries. For 100 nodes at 256 vnodes each, that's 25,600 positions — trivial in memory, but you're now maintaining a sorted data structure that must stay consistent across all clients.
In a system where multiple clients independently maintain a ring, ring updates need to be propagated to all clients. If one client adds a node before another client has updated its ring, they route the same key to different servers. The window is usually milliseconds, but it means your cache layer is briefly inconsistent. For a cache this is fine — you get a miss, not a corruption. For a stateful system, it requires more care.
The deeper tradeoff: consistent hashing solves the rebalancing disruption problem, not the distributed systems coordination problem. You still need to handle the migration window, replication lag, and the operational complexity of a system that's actively reshuffling data. What consistent hashing buys you is the assurance that the reshuffling is proportional — not a full avalanche every time the topology changes.
That assurance is worth a lot. The database that buckled under a cache miss storm after the 11th server was added? Consistent hashing is why that specific failure mode doesn't exist in systems like Cassandra and Redis Cluster. They can add capacity without rerouting the world. That operational property — adding nodes without incident, at any time, under any traffic — is what consistent hashing is actually for.
More in System Design
Building a Distributed Job Scheduler
Why single-node job schedulers silently fail in production, and how to build a distributed scheduler with leader election, task deduplication, and failure recovery.
Designing a Reliable Webhook Delivery System
How to build a webhook delivery system that handles retries, dead letter queues, and delivery guarantees without hammering failing endpoints or losing events.