Achieving Exactly-Once Delivery in Kafka: Theory vs Practice
How Kafka's idempotent producers, transactional APIs, and consumer coordination achieve exactly-once semantics — and when at-least-once is the smarter choice.

Akhil Sharma
January 14, 2026
Achieving Exactly-Once Delivery in Kafka: Theory vs Practice
The distributed systems textbook says exactly-once delivery is impossible. Kafka says they've done it. Both are right — the nuance lies in what "exactly-once" actually means and the boundaries within which Kafka's guarantees hold.
The Theory: Why Exactly-Once Is "Impossible"
The Two Generals' Problem proves that no protocol can guarantee message delivery in the presence of unreliable communication. A producer sends a message, the broker stores it, but the acknowledgment is lost. The producer doesn't know if the message was stored or not. It retries — and now the message might be duplicated.
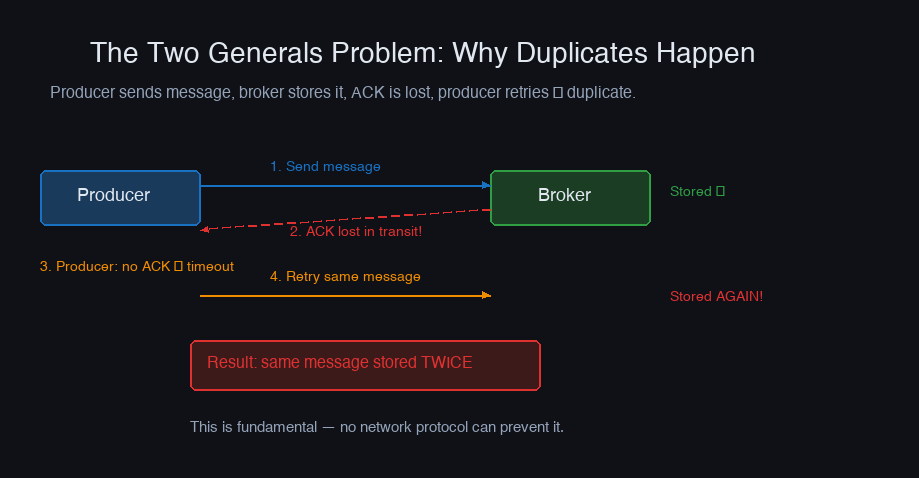
Kafka doesn't solve the Two Generals' Problem. Instead, it narrows the scope: exactly-once within the Kafka ecosystem, between producers and consumers connected to the same Kafka cluster. Once a message leaves Kafka and hits an external system (database, API), you're back to at-least-once.
Idempotent Producers: Deduplication at the Broker
Kafka's first exactly-once building block is the idempotent producer. When enabled, each producer gets a unique Producer ID (PID), and each message gets a monotonically increasing sequence number. The broker deduplicates by tracking (PID, partition, sequence_number).
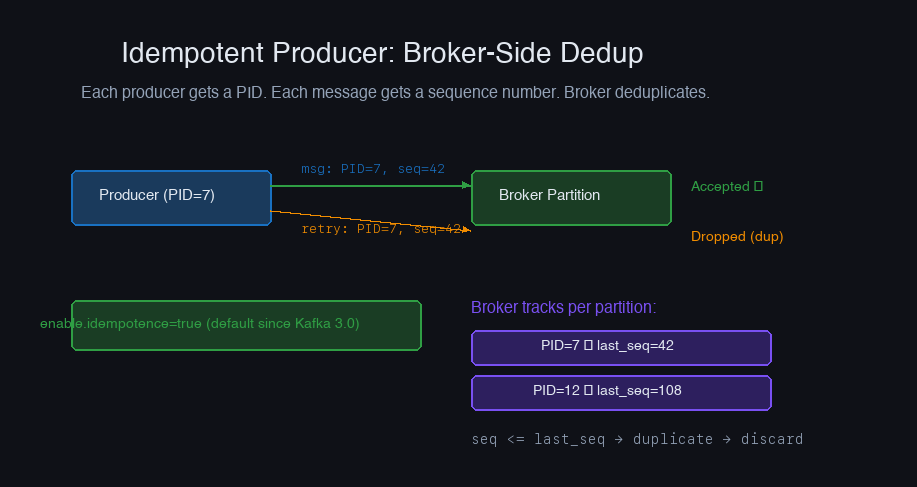
With idempotence enabled, the producer can safely retry without creating duplicates. The broker sees "I already have sequence 42 from PID 7 on partition 3" and silently drops the duplicate.
What idempotent producers don't do: They prevent duplicates within a single producer session. If the producer crashes and restarts, it gets a new PID, and the deduplication state resets. For cross-session guarantees, you need transactions.
Transactions: Atomic Multi-Partition Writes
Kafka transactions let a producer atomically write to multiple partitions and commit consumer offsets. Either all writes succeed or none of them are visible.
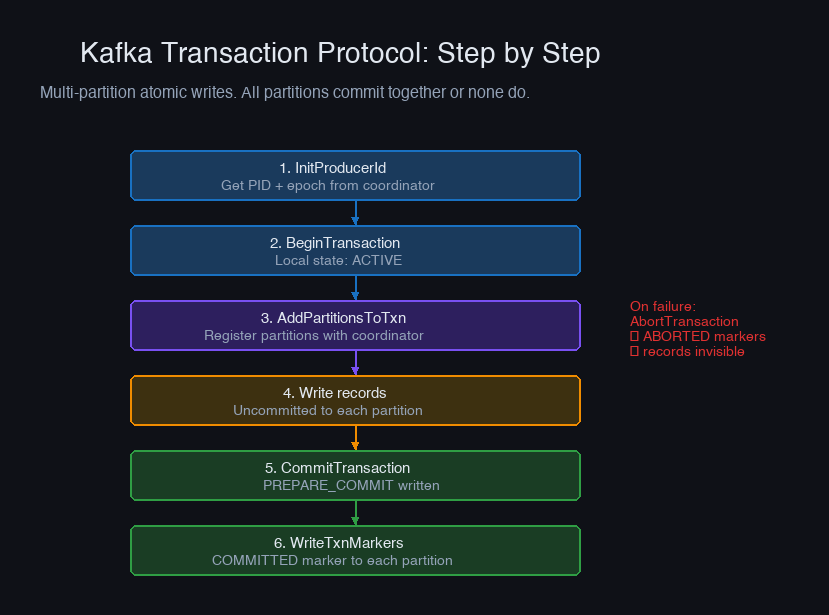
The transactional.id is persistent across restarts. When a producer starts with a transactional ID that was previously in use, Kafka fences the old producer (any in-flight transactions from the old instance are aborted). This prevents zombie producers from creating duplicates after failover.
How Transactions Work Internally
Advanced System Design Cohort
We build this end-to-end in the cohort.
Live sessions, real systems, your questions answered in real time. Next cohort starts 2nd July 2026 — 20 seats.
Kafka uses a transaction coordinator (a broker designated for each transactional.id) and a transaction log (__transaction_state topic):
Records written during a transaction are physically present on the partition but marked as uncommitted. They become visible only after the commit marker is written. Consumers with isolation.level=read_committed skip uncommitted records.
Consumer-Side: read_committed
On the consumer side, you need to opt into transactional guarantees:

With read_committed, the consumer's position advances to the Last Stable Offset (LSO) — the offset of the earliest in-flight (uncommitted) transaction. This means a long-running transaction blocks downstream consumers from reading anything past its start offset, even committed records that come after it.
Implication: Keep transactions short. A transaction that runs for 30 seconds blocks all read_committed consumers on that partition for 30 seconds.
The Consume-Transform-Produce Pattern
The canonical exactly-once pattern in Kafka: read from input topic, process, write to output topic, and commit consumer offsets — all in one atomic transaction.
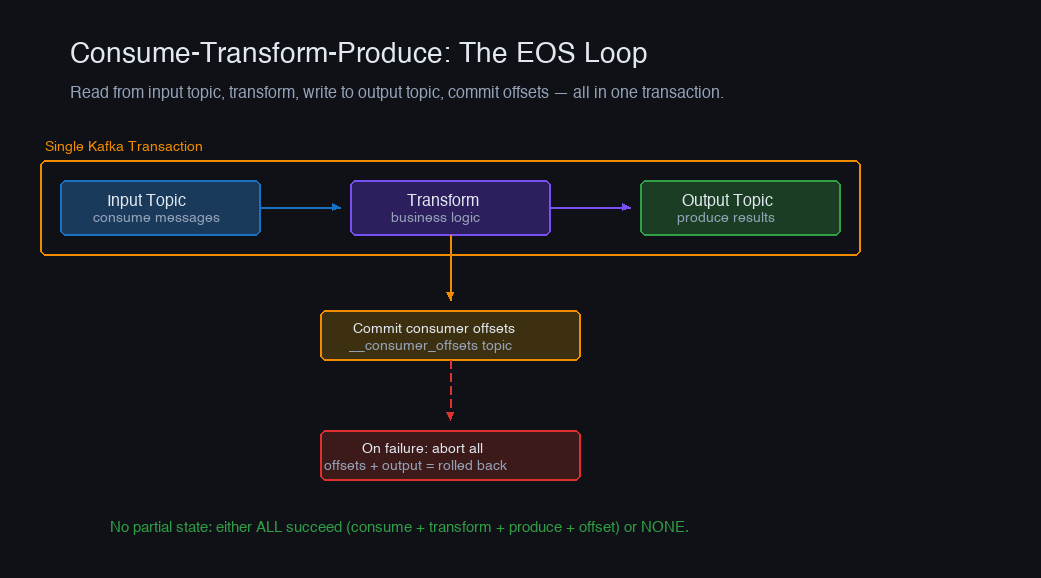
This guarantees that each input record produces exactly one output record. If the transaction aborts, both the output records and the offset commit are rolled back, so the consumer re-reads and re-processes.
Performance Overhead
Transactions aren't free. Here's what they cost:
| Metric | Without Transactions | With Transactions | Overhead |
|---|---|---|---|
| Producer throughput | 850K msgs/sec | 600K msgs/sec | ~30% |
| Producer latency (p50) | 2ms | 5ms | +3ms |
| Producer latency (p99) | 15ms | 45ms | +30ms |
| Consumer throughput | 1.2M msgs/sec | 900K msgs/sec | ~25% |
Benchmarked on 3-broker cluster, replication factor 3, 6 partitions, message size 1KB.
The overhead comes from:
- Extra RPCs to the transaction coordinator
- Transaction markers written to each partition
- Consumer buffering until commit markers arrive
When At-Least-Once Is Better
Exactly-once in Kafka only covers Kafka-to-Kafka processing. The moment you write to an external system (database, API, cache), the guarantee breaks:
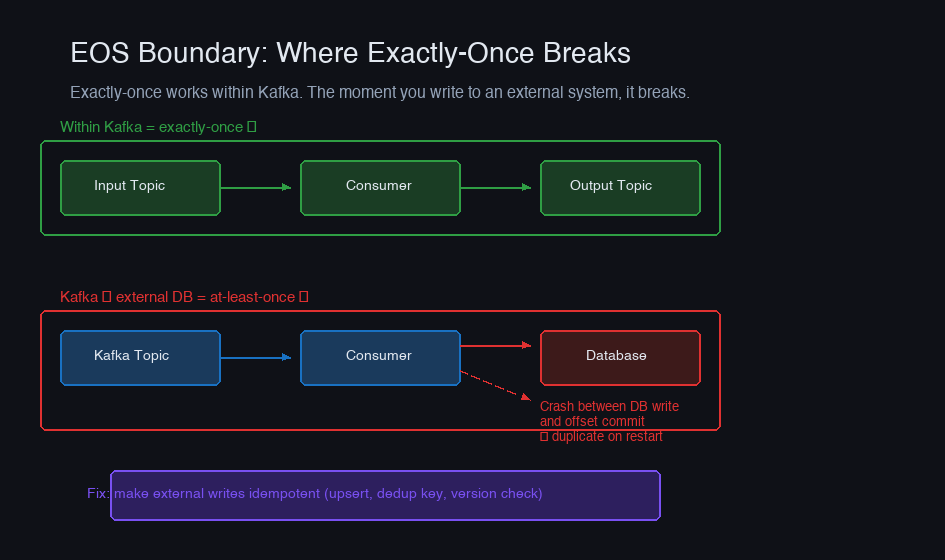
For most real-world applications, the answer is: use at-least-once delivery with idempotent consumers. Design your consumer's side effects to be idempotent:
This is simpler, faster (no transaction overhead), and covers the external-system case that Kafka transactions can't. Kafka transactions are the right choice for Kafka Streams applications and consume-transform-produce pipelines that stay within Kafka. For everything else, invest in idempotent consumers.
Configuration Pitfalls
Common misconfigurations that silently break exactly-once:
-
acksnot set toall: Idempotent producers requireacks=all. Without it, a leader failure before replication can lose the deduplication state. -
transaction.timeout.mstoo low: Default is 60 seconds. If your processing takes longer, the transaction aborts. Set it to match your worst-case processing time plus margin. -
Reusing
transactional.idacross unrelated producers: Each transactional ID should map to exactly one logical producer. Sharing IDs causes fencing storms. -
Not handling
ProducerFencedException: This means another producer instance took over your transactional ID. Don't retry — shut down the old instance. -
Consumer
auto.commitenabled with transactions: Auto-commit bypasses the transactional offset commit. Always disable it when using consume-transform-produce.
Kafka's exactly-once is real, but it's exactly-once within Kafka. Know the boundaries, measure the overhead, and consider whether idempotent at-least-once covers your actual requirements. Most of the time, it does.
More in System Design
Building a Distributed Job Scheduler
Why single-node job schedulers silently fail in production, and how to build a distributed scheduler with leader election, task deduplication, and failure recovery.
Consistent Hashing in Practice
Why modulo hashing silently nukes your cache every time you scale, and how consistent hashing solves the rebalancing problem that takes down databases.