Event-Driven Architecture Pitfalls I've Seen in Production
Common failure modes in event-driven systems — ordering, schema evolution, duplicate handling, and the dual-write problem — with practical solutions.

Akhil Sharma
February 10, 2026
Event-Driven Architecture Pitfalls I've Seen in Production
Event-driven architecture (EDA) promises loose coupling, scalability, and resilience. In practice, it delivers all three — plus a set of failure modes that are uniquely difficult to debug. Here are the pitfalls I've encountered across multiple production systems, and how to avoid them.
Pitfall 1: The Dual-Write Problem
The most common EDA bug. A service needs to update a database AND publish an event. If either fails after the other succeeds, the system is inconsistent.

This isn't a theoretical problem. Network partitions, process crashes, and deployment restarts all cause it. I've seen order fulfillment systems where 0.1% of orders were never processed because the event was lost.
Solution: The Outbox Pattern
Write the event to a database table (the "outbox") in the same transaction as the business data. A separate process reads the outbox and publishes to Kafka.
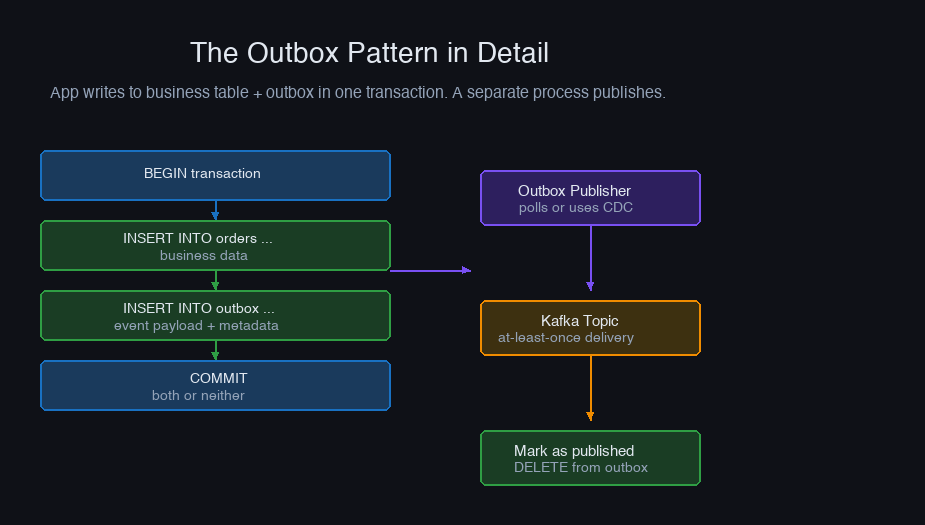
The outbox publisher (using Debezium CDC or polling):
The database transaction guarantees atomicity. If the transaction rolls back, both the order and the event are gone. The outbox publisher handles delivery to Kafka with retries.
Pitfall 2: Event Ordering Assumptions
Teams assume events arrive in the order they were produced. For a single partition in Kafka, this is true. Across partitions, it's not. And even within a partition, consumer rebalancing can cause out-of-order processing.

Solutions
1. Partition by entity key. All events for the same order go to the same partition (keyed by order ID). Within a partition, order is preserved.
2. Include sequence numbers. Each event carries a version/sequence number. Consumers reject or reorder events that arrive out of sequence.
Advanced System Design Cohort
We build this end-to-end in the cohort.
Live sessions, real systems, your questions answered in real time. Next cohort starts 2nd July 2026 — 20 seats.
if event_version > current_version + 1: # Gap detected — buffer this event and wait await buffer_event(event) return
await process_event(event)
Compatibility rules:
- Backward compatible: New consumers can read old events. (Add optional fields, don't remove or rename required fields.)
- Forward compatible: Old consumers can read new events. (Don't add required fields.)
- Full compatible: Both directions. (Only add optional fields.)
Practical rule: Always add fields as optional with defaults. Never remove or rename fields — deprecate them and add new ones. This keeps backward compatibility without requiring consumer updates.
Pitfall 4: Duplicate Event Handling
In distributed systems, messages can be delivered more than once. Consumer crashes, Kafka rebalances, network retries — all cause duplicates. Your consumers must be idempotent.
The processed_events table acts as a deduplication log. Wrap it in the same transaction as the business logic to prevent partial processing.
Cleanup: The deduplication table grows. Periodically purge entries older than your Kafka retention period — events older than that won't be replayed.
Pitfall 5: Event Storms
A cascade where one event triggers multiple downstream events, each triggering more events, overwhelming the system. I've seen a single user profile update trigger 2,000+ events across a dependency chain.
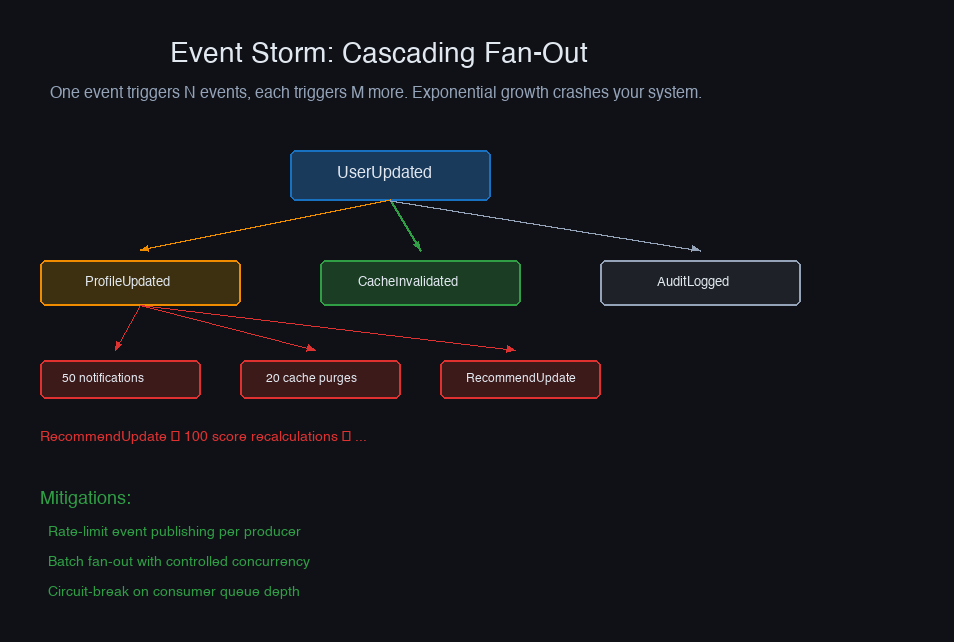
Solutions
1. Debounce at the source. If a user rapidly updates their profile, don't emit an event for each keystroke. Batch changes and emit one event after a quiet period.
2. Rate limit event consumers. Process at most N events per second per consumer. Buffer the rest.
3. Distinguish domain events from integration events. Internal events (within a service boundary) can be chatty. Events published to Kafka (crossing service boundaries) should be coarse-grained. Don't publish every internal state change — publish meaningful business events.
Pitfall 6: Debugging Black Holes
In a synchronous system, a request fails and you get a stack trace. In an event-driven system, a request produces an event, which triggers a consumer, which produces another event, which triggers another consumer — and something fails three hops away. The original request returned 200 OK twenty minutes ago.
Solutions
1. Correlation IDs. Every event carries a correlation ID from the original request. All downstream events and logs include this ID.
2. Dead letter queues (DLQs). Failed events go to a DLQ instead of being silently dropped or blocking the consumer. Monitor DLQ depth as a health metric.
3. Event flow visualization. Build a dashboard that shows event flow across services for a given correlation ID. When debugging, you can see exactly where in the chain the failure occurred. Tools like Jaeger with custom spans per event hop work well for this.
Event-driven architecture isn't inherently harder than synchronous architecture — it's differently hard. The failure modes are less obvious, the debugging is harder, and the correctness guarantees require explicit effort. But the patterns above (outbox, idempotency, correlation IDs, schema evolution) are well-understood and battle-tested. The teams that struggle are the ones who adopt EDA without adopting these patterns.
More in System Design
Building a Distributed Job Scheduler
Why single-node job schedulers silently fail in production, and how to build a distributed scheduler with leader election, task deduplication, and failure recovery.
Consistent Hashing in Practice
Why modulo hashing silently nukes your cache every time you scale, and how consistent hashing solves the rebalancing problem that takes down databases.